跟雷神学音视频-3.音视频压缩编码基本原理
视频编码基本原理
为什么需要编码
记录数字视频的YUV分量格式为例,YUV分别代表亮度与两个色差信号。其中Y采样频率为13.5MHz,色度信号一般为一半或更少,为6.75或3.375MHz。以4:2:2采样频率为例,采样信号以8bit量化,码率为:
13.5 8 + 6.75 8 + 6.75 * 8 = 216Mbit/s,数字量非常的大,因此需要压缩以减少码率。
视频码率就是数据传输时单位时间传送的数据位数,一般我们用的单位是kbps即千位每秒。通俗一点的理解就是取样率,单位时间内取样率越大,精度就越高,处理出来的文件就越接近原始文件。
哪方面入手压缩
数据冗余。 空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性,可以消除。属于无损压缩。
视觉冗余。利用人眼的特性,亮度辨别阈值、视觉阈值,引入适量误差,以一定的失真换取数据压缩。属于有损压缩。
通常使用变换编码来消去除图像的帧内冗余,用运动估计和运动补偿来去除图像的帧间冗余,用熵编码来进一步提高压缩的效率。
压缩编码的方法
变换编码
作用是将空间域描述的图像信号变换到频率域 ,变换到频率域可以实现去相关和能量集中 ,然后对变换后的系数进行编码处理。 常用的正交变换有离散傅里叶变换,离散余弦变换等等。数字视频压缩过程中应用广泛的是离散余弦变换。
离散余弦变换简称为DCT变换。 它可以将L*L的图像块从空间域变换为频率域。 将图像分成互不重叠的图像块再进行DCT变换。
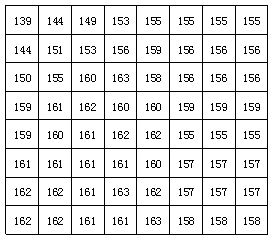
下图是上图中图像块经过DCT变换后的结果。从图中可以看出经过DCT变换后,左上角的低频系数集中了大 量能量,而右下角的高频系数上的能量很小。
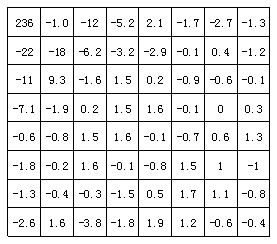
量化过程通过对低频区的系数进行细量化,高频区的系数进行粗量化,去除了人眼不敏感的高频信息,从而降低信息传送量,此处是视频压缩中操作的主要原因。
量化的过程可以用下面的公式表示:
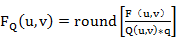
其中FQ(u,v)表示经过量化后的DCT系数;F(u,v)表示量化前的DCT系数;Q(u,v)表示量化加权矩阵;q表示量化步长;round表示归整,即将输出的值取为与之最接近的整数值。

DCT系数经过量化之后大部分经变为0,而只有很少一部分系数为非零值,此时只需将这些非0值进行压缩编码即可。
熵编码
熵编码多用可变字长编码(VLC,Variable Length Coding)实现。其基本原理是对信源中出现概率大的符号赋予短码,对于出现概率小的符号赋予长码,从而在统计上获得较短的平均码长。 可变字长编码通常有霍夫曼编码、算术编码、游程编码等。游程编码的压缩效率不高,但编码、解码速度快。
输出直流系数后对紧跟其后的交流系数进行Z型扫描(如图箭头线所示)。Z型扫描将二维的量化系数转换为一维的序列,并在此基础上进行游程编码。最后再对游程编码后的数据进行另一种变长编码,例如霍夫曼编码。通过这种变长编码,进一步提高编码的效率。
运动估计和运动补偿
消除图像序列时间方向相关性的有效手段。 1和2都是消除同帧图像内的像素在空间上的相关系。但是帧和帧的相关信即时间上的相关系由此进行消除,如果两帧之间背景变化不大,那就没必要每一帧单独进行编码,而只对相信帧中变化的部分进行编码。
运动估计:一般将当前的输入图像分割成若干彼此不相重叠的小图像子块,在前或后帧的搜索范围内为每个子块寻找最相似的图像子块。
运动补偿:计算两个子块会得到一个运动矢量。将当前图像的块与参考图像运动矢量所指向的最相似的图像块相减,得到残差图像块;这样可以得到更高的压缩比。
图像帧分为: I(Intra)帧、B(Bidirection prediction)帧、P(Prediction)帧。
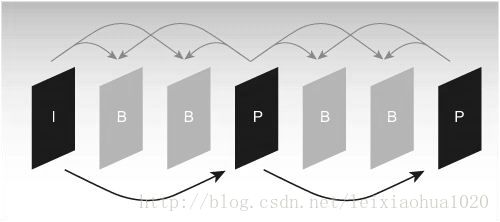
I帧只使用本帧内的数据进行编码,在编码过程中它不需要进行运动估计和运动补偿。
P帧在编码过程中使用一个前面的I帧或P帧作为参考图像进行运动补偿,实际上是对当前图像与参考图像的差值进行编码 。
B帧的编码方式与P帧相似,惟一不同的地方是在编码过程中它要使用一个前面的I帧或P帧和一个后面的I帧或P帧进行预测。
综合
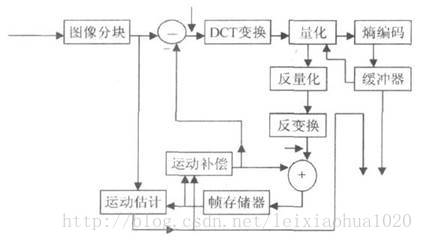
图像经过分块,得到的图像块与经过运动补偿的预测图像相减得到差值图像,然后对差值图像进行DCT变换和量化,量化输出的数据有两个去处:1.送给熵编码器编码,编码后的码流输出到缓存器中,等待传送。2.进行反量化和反变化后得到信号,该信号与运动补偿输出的图像块相加得到新的预测图像信号,并将新的预测图像块送至帧存储器。
音频编码基本原理
为什么需要编码
一套双声道数字音频,取样频率为44.1KHz,每样按16bit量化,则其码率为:2 44.1 16 = 1.411 Mbit/s
哪方面入手压缩
去除不能被人耳感知到的信号(20Hz~20KHz),即听觉范围外的音频信号以及被掩蔽掉的音频信号。当同时存在强弱音频时,掩蔽弱音信号。
频谱掩蔽效应
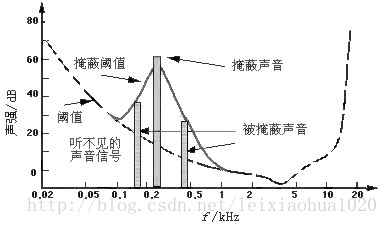
简单来说,人耳对音频有一定的限制,过高或者过底都听不见,同一音频不同的声贝也有可能听不见。因此可以根据这个条件去掉一部份音频。但是如果某音频的音贝提高了,临近的阈值也会提高,所以可以去除掉这一部份的音频。如下图所示:
0.2kHz处出现60dB的声音时,0.1至1kHz的阈值都升高了,虚线以下的声音都需要去除掉,不必传送。
时域掩蔽效应
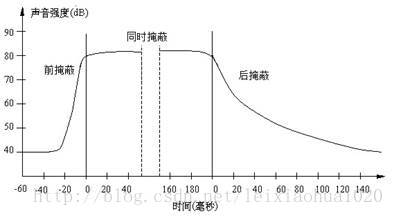
当强弹音信号同时发出时,还存在时域掩蔽效应。前掩蔽指听到强信号之前短暂时间内,已经存在的弱信号会被掩蔽而听不到。同时掩蔽指同时存在,弱信号会被强信号掩蔽。后掩蔽指强信号消失后,经一段时间才能重新听见弱信号。被掩蔽的弱信号可视为冗余信号。
压缩编码的方法
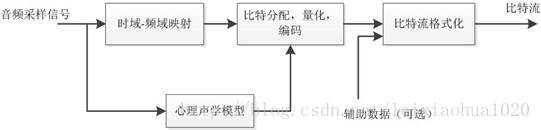
对于每个音频声道中的音频采样信号,先从时域映射到频域中(子带滤波器)。音频采样块根据心理声学模型计算掩蔽门限值,由此来决定公共比特池中分配给该声道的不同频率域中多少比特数,接着进行量化以及编码工作,最后结合控制参数及辅助数据,产生编码后的数据流。
本文标题:跟雷神学音视频-3.音视频压缩编码基本原理
文章作者:whppmy
发布时间:2019-11-26
最后更新:2019-11-26
原始链接:http://bugnull.com/视频图像/跟雷神学音视频-3-音视频压缩编码基本原理/
版权声明:个人记录,没有获取同意时,禁止转载!!